The Enterprise Canvas, Part 6: Models
After that rather lengthy wander through context and value, market and supply-chain, owners and managers, layers and recursion, we now have our complete Enterprise Canvas. Time to put this model-type to practical use.
There’ll be a lot of cross-references in what follows, so for brevity’s sake here’s a version of the complete Canvas with simple two-letter codes assigned to each cell, flow and external party:
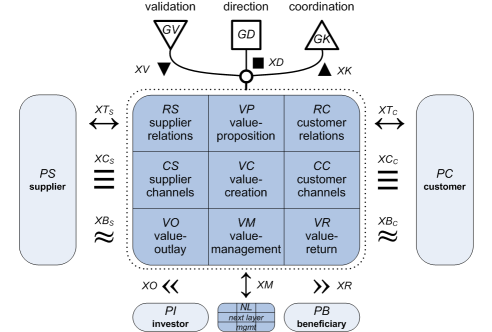
The Canvas model assumes that the enterprise can be described in terms of – and hence consists of – any number of interrelated services, each of which can be described at any appropriate level of abstraction and granularity – see Part 4: Layers. Each instance of a Canvas describes a single service at a single layer of abstraction, in context of the flows and interchanges it shares with each of its stakeholders.
We really do first need to know the enterprise vision and values, in order to know what ‘value’ is and means within any part of the enterprise. If we don’t already have it, we need to start at row-0 to set that in place. (We can sometimes infer the content of the Enterprise layer from the various value-propositions on offer by the organisation, but architecturally it’s a risky tactic, particularly when – as is all too often the case – the values and value-propositions are inconsistent with each other and will be based primarily on what happened in the past. Far better to do the extra work upfront to establish a stable foundation that will apply to past, present and future.) Once we do have that Enterprise layer in place, though, we can start anywhere, with any service, at any level, anywhere in the organisation and extended-enterprise.
The modelling process is exactly the same in every case, whether we want to do an as-is, an as-was or a to-be model for the respective service that is the focus of this Canvas.
The Canvas is also holographic: every service ultimately connects with everything else, hence any assessment we do in any part of the enterprise implicitly contributes to the detail of everywhere else. So we don’t need to try to gather every possible piece of information about everything in ‘excruciating detail’, as John Zachman once put it; instead, we start anywhere that seems appropriate, model only what we need for that specific task, link the models together wherever practicable and appropriate, and allow the overall detail to emerge over time through the layering and interconnections of the Canvas structure.
So: start somewhere. Anywhere will do. It doesn’t need to be a ‘service’ as such – just an area of interest, an aspect of the organisation or enterprise where something happens.
What layer is it, in terms of the Enterprise Canvas? To put it another way round, how abstract is it? or how concrete? Use the descriptions in the layers article to identify which layer you want to be working on. (The important point here: don’t mix layers. Each layer has a different architectural function, and you create architectural risks if you blur them together. If you need to see how something changes across layers – going from row-3 abstract to row-4 implementation-design, for example, or from an actual row-5 implementation back up to row-3 to rethink alternate options – then use a separate Canvas for each layer, and link them together via GV/GD/GK oversights [see the labels in the diagram above] and/or via XV/XD/XK or XM service-interfaces and flows. Don’t mix them up!)
Next, we use the tetradian dimensions – physical, conceptual, relational, aspirational – to summarise the nature of the service (or whatever-it-is):
- What does it do? (‘physical‘) What services or products or other ‘deliverables’ does this create through its work? (The answers define the role and emphasis of the Canvas’ Value-Creation cell.)
- For whom or for what does it do this? With whom or with what does it relate? (‘relational‘) Via what transactions and flows does it deliver? (The answers define the role and content of each of the flows, with an emphasis on each of the ‘supplier-side’ and ‘customer-side’ cells and the XC interfaces, and the direct transactional stakeholders.)
- What information does it need, to guide and plan and schedule and improve what it does? (‘conceptual‘) With whom or what does it need to share this information? (The answers define the role of the Value-Management cell, with some emphasis on the Value-Outlay and Value-Return cells and the XK, XD, XM and other interfaces.)
- Why does it do what it does? (‘aspirational‘) What value does this add for each of its stakeholders, and for the overall enterprise? (The answers define and emphasise the role of the Value-Proposition cell, and key aspects of the Customer-Relations, Supplier-Relations, Value-Outlay and Value-Return cells, the XV, XT, XB, XO and XR interfaces, and the non-transactional stakeholders.)
Repeat the process for each of the cells (Vx, Rx, Cx), each of the flows (Xx), and each of the stakeholder-relationships (Px): What does it do? For and/or with whom or what does it do this? What information does it need? Why does it do this?
For example, often the service will need some form of investment to get it started, or keep it going (XO interface, linking between VO cell and PI or other stakeholder). What is this investment? What value and/or values does it represent? (Remember to think of ‘value’ in more than solely monetary terms.) What does this investment do? From whom does this investment come? What information is required to determine what investment will be needed? Why is this investment needed? and so on.
Explore the service’s needs for the guidance services (GV, GD, GK) that connect this to other parts of the enterprise and its values:
- Who or what provides run-time coordination (GK) with other services? Identifies and coordinates medium-term change of this service (such as via change-projects, -programmes or -portfolios), in parallel with other services? Develops overall potential for value-creation, in conjunction with other services?
- Who or what provides operational or run-time direction (GD) for this service and its sibling-services? (What are this service’s sibling-services? What do they do? Why?) Who or what provides business-intelligence and other guidance for medium-term transition from strategy to tactics for this service? Who or what links this service to the overall enterprise to identify appropriate longer-term strategy?
- Who or what ensures validation (GV) and alignment to enterprise values, principles, rules and regulations? (What values and and the like will apply to this service? Why? What are their relative priorities, and why? What values and principles do not apply? Why not?) Who or what develops awareness within this service of the need, importance and application of each value, principle and so on? Who or what assists this service in developing its capability to enact and align with that value? Who or what will monitor, audit and assure compliance with each value within this service?
- What interchanges, flows and interfaces are needed to support, guide, coordinate and validate all of this?
- What value does all of this provide to the service, in delivering its value-proposition to the enterprise? What impacts and constraints would apply to this service in the short-, medium- and longer-term if this coordination, direction and/or validation does not occur?
With all of that in place, we now have some solid understanding of what this service does, and why, and for and with whom. We now need to look more closely at the ‘how’ and ‘with what’ of the service – for example, that which the Business Model Canvas describes as Key Activities and Key Resources. As described in various of the earlier articles, one of the best frames with which to assess the interfaces and flows is VPEC-T – Values, Policies, Events, Content, Trust – though we do need to remember to pay especial attention to the ‘front end’ of the market-sequence (reputation > trust > respect > attention > conversation), all of which will precede transaction, exchange and any potential and/or future profit. For the service itself, and for each of its cells – especially Value-Creation – another valuable frame is the extended-Zachman, adapting the standard IT-oriented Zachman frame for use in the much broader scope of whole-of-enterprise architecture. The full version of the extended-Zachman frame requires three dimensions – rows, columns and asset/decision-category segments – but in this case we already know the applicable row, so we can use a simpler grid-type layout:

Note the somewhat different meanings of the columns here compared to standard-Zachman – particularly the ‘Capabilities’ or ‘Who’ columns. These differences are extremely important, because without them the standard-Zachman frame is too IT-oriented for use in a whole-of-enterprise scope. One side-effect is that, by intention, there is no actual person (no ‘who’) in this version of the frame, because individual people are not assets: the capabilities that we need from people, for example, can only be accessed via something that actually is an asset of the enterprise, namely the relationship that it has with that person.
Functions act on Assets to change them (i.e. create value); a Function needs to be linked to appropriate Capabilities in order to do so (which creates a service). Overall, we can summarise as follows:
with Asset do Function using Capability at Location on Event because Decision
Assets, functions, locations, capabilities and events all are, act on or are triggered by the various asset-types: physical ‘things’, virtual information, relations between people, or ‘aspirational’ links between people and abstract ideas or beliefs or values – see the explanation of asset-types in the ‘Market and Supply-Chain‘ article for more detail on this. For example, an event may be triggered by a actual incident (physical event), a specific value in a parameter (virtual event), the arrival of a person in a shop (a relational event) or a merger between two companies (a change of ‘belief and belonging’, hence an aspirational event). In this context, many if not most real-world items are actually composites or aggregations of different asset-types: for example, a book is a ‘thing’ (physical) that contains and carries information (virtual).
(Two other quick notes. Time is best understood as a location – events occur in time, but time itself is not an event. And whilst some people might class money as a special case of abstract, it’s actually better understood as a simple composite of virtual and aspirational, as information about a belief in future ‘rights’ of access to assets. All a bit technical, perhaps, but actually quite important once we start to explore in depth how value actually works within enterprise-architectures.)
Decision-levels and skill-levels are somewhat different but are closely-related. The Cynefin categorisation can also be useful here: the skill-levels of simple rule-based, algorithmic, guidelines/heuristics and principle-based are likely to be needed in contexts that respectively match the Cynefin categories of Simple, Complicated, Complex and Chaotic. One important point is that there’s a cross-alignment with the asset-types here: physical machines in general can only follow simple rules; IT-systems can also manage complicated algorithms for decision-making; real people with real skills are needed to handle true complexity; and very high skill-levels are needed to work within ‘chaotic’ contexts where nothing ever actually repeats. One of the most serious problems to affect organisations in recent times has been the repeated attempts to use IT for complex or ‘chaotic’ contexts where, by definition, it is simply not suitable: for example, this was a key cause of failure in many attempts at IT-driven ‘business process re-engineering’.
So: apply this extended-Zachman frame to the service in focus on the Enterprise Canvas, and to each of its cells:
- What assets, functions and capabilities are required here? What asset-type categories are involved in each case?
- In which locations do they occur? Of what asset-type categories are these locations: a physical place, a virtual-address, a reporting-relationship or other social-network location, a point in time?
- What events and event-types trigger these activities? (Cross-reference to the previous VPEC-T assessments on external flows, and perhaps apply similar analysis to any internal flows between cells.)
- What skill-levels and decision-types apply in each case? – rule-based, algorithmic, pattern-based guideline or heuristic, and/or principle-based?
Next, apply a RACI frame to identify responsibilities for each item, activity, event and decision within the service and its cells, within and for each flow or interchange, and the equivalent responsibilities in and of each stakeholder:
- Who is responsible for this, and any changes to this? – “those responsible for the performance of the task”
- Who assists in this, and any changes to this? – “those who assist in the completion of the task”
- Who should be consulted about this, and any changes to this? – “those whose opinions are sought, and with whom there is two-way communication”
- Who should be informed about this, and any changes to this? – “those who are kept up-to-date on progress, and with whom there is (usually) one-way communication”
- Optionally, who does not need to be (or should not be) responsible, accountable, consulted and/or informed about this, or any changes to this? (e.g. an executive does not normally need detailed reports about every minor operational change)
There should always be one person who is uniquely responsible for any item; and, equally, every item needs one person who is uniquely responsible for it at all times. Look for overlaps in responsibilities (often occurring in transitions between layers – for example, one person has operational responsibility for an item, another has tactical responsibility, another the strategic responsibility). Perhaps even more important, look for gaps in responsibilities, where no-one has apparent responsibility or where the responsibility has been nominally assigned but not actually taken up or enacted. (Note that simply assigning someone responsibility does not necessarily mean that that responsibility is taken up! – functional responsibility is an active choice, not an arbitrary label.)
Also note that real responsibility can only be held by a real person: a machine or an IT-box is not capable of taking ultimate responsibility for anything – hence, especially wherever IT or machines are involved, it may be necessary to follow lengthy trails of non-responsibility (or evasions of responsibility…) in order to identify the actual responsible person. And, finally, a person can only be responsible for something if they also have the authority and competence to make the required decisions: if they don’t have that authority or competence, they cannot and must not be considered responsible or accountable for the respective item, and hence a further search for someone who can have both responsibility and authority will need to be made. (Note that such mismatches of responsibility, authority and competence are extremely common, especially in dysfunctional organisations.)
Next, do a SWOT assessment on the overall service, and on each of its cells, its flows and its links with each of its stakeholders, and on the links up and down the rows, from abstraction (redesign) to implementation. (For this purpose I would actually recommend my own extended variant of SWOT, called SCORE – Strengths, Challenges, Opportunities/risks, Rewards, Effectiveness – but I would have to admit that SWOT is better-known. 🙂 )
- What are the Strengths in this context? Which of these strengths – if any – is underutilised, or could be applied in other, even more effective ways?
- What are the Weaknesses in this context? What impacts could or do these have on operations, on tactics, on strategy? In what ways could these challenges be redressed or mitigated?
- What are the external Opportunities in this context? In what ways could these opportunities be exploited? What concomitant risks do each of these opportunities imply?
- What are the external Threats in this context, from what and/or from whom? In what ways could these risks be redressed or mitigated? What concomitant opportunities do these risks imply?
Another useful frame here is one that I documented in my book Real Enterprise Architecture – a 5×5 matrix that links lifecycles and effectiveness:
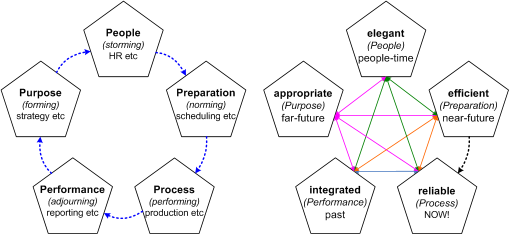
The lifecycle part of the matrix – shown on the left-hand side of the diagram above – is derived in part from Bruce Tuckman’s well-known Group Dynamics project-lifecycle: forming, storming, norming, performing, adjourning. For the service overall, for each of its cells, and for each of its flows, we need to ask:
- Who or what is responsible for the Purpose of this item? (This should link strongly with the Value-Proposition cell, for example, and also the ‘direction’ guidance-services.)
- Who or what is responsible for the People-issues for this item? (This is where the ‘validation’ guidance-services are likely to play a key part in the service and, for external links, the Supplier/Customer-Relations cells.)
- Who or what is responsible for the Preparation and scheduling for this item? (This should link strongly with the Value-Management cell, and also the ‘coordination’ guidance-services.)
- Who or what is responsible for the Process and action of this item? (This should link strongly with the Value-Creation cell, probably the Supplier/Customer-Channel cells, and probably also the ‘coordination’ guidance-services.)
- Who or what is responsible for the overall Performance of this item, including completions and lessons-learned? (This should again link strongly with the Value-Management cell, the Valoue-Outlay/Return cells, and also the ‘validation’ guidance-services.)
Serious architectural problems will occur if these elements are out of balance – which they often are, in real-world practice. In commercial organisations, for example, there’s often a strong tendency to attempt to short-cut the cycle, jumping from the early stages of the Performance phase – the point at which monetisation occurs – back to the start of the Preparation phase – so as to return to Process and purported profit as quickly as possible; lessons-learned, long-strategy and people-issues are all minimised and glossed-over as ‘unnecessary overhead’. The result does deliver higher gains in the short-term – because the costs of the skipped-over phases are avoided – but will inevitably lead to longer-term failure. Identifying and resolving such imbalances is a key task for whole-of-enterprise architecture.
The effectiveness part of the matrix – shown on the right-hand side of the diagram – also crosslinks to the lifecycle part, as can be seen in the secondary captions for each of the five effectiveness-domains. For the service overall, for each of its cells, and for each of its flows, we need to ask, everywhere, and in every way:
- Is it Efficient? – maximises use of resources, minimises wastage of resources
- Is it Reliable? – predictable, consistent, self-correcting, supports ‘single source of truth’
- Is it Elegant? – clarity, simplicity, consistency, self-adjusting for human factors
- Is it Appropriate? – supports and maximises support for business purpose
- Is it Integrated? – creates, supports and maximises synergy across all systems
The aim here is that everything should fit in with and support everything else: these questions help to identify where they do, where they don’t and, if they don’t, what to do about it. 🙂
Before we move on to real examples, I’ll recommend one final frame for additional crosschecks: SEMPER. I’ll admit this is another of my own tools, but one I’ve found immensely value in assessing ability to do work within a context. The point here is whilst the physics definition of ‘power’ approximates to ‘the ability to do work’, many social definitions of ‘power’ are more like ‘the ability to avoid work’ – and therein lie some huge problems for organisations and for enterprise-architectures. It’s actually based on the tetradian model, as described earlier above, but the SEMPER-5 variant crosslinks with the lifecycle/effectiveness matrix and uses a simple 1-5 scale to identify potential problems across a context, and suggest options for action to resolve them. All I can say is try it, see what you think – but my experience is that it does work well for the kind of contexts we cover with the Enterprise Canvas.
So, that’s one suggested set of models that you could use with the Enterprise Canvas – where the Canvas becomes a base-map for deep exploration, a “one map to rule them all” and bind them together to create new insights about the overall architecture. Yes, it’s a lot of work: but then anyone who thought that it wouldn’t be a lot of work probably hasn’t done much real-world enterprise-architecture… 🙂
Enough for now, anyway: in the next article we’ll look at some examples of what this all looks like in real-world practice.
Leave a Reply