The Enterprise Canvas, Part 4: Layers
In the first part of this series of articles we explored context and values; in the second part we linked this to the market and supply-chain, and the related flows that pass in the ‘horizontal’ channels between services; and in the third part we added the flows that link the service to its investors, beneficiaries and managers. We ended up with a frame that looks like this:
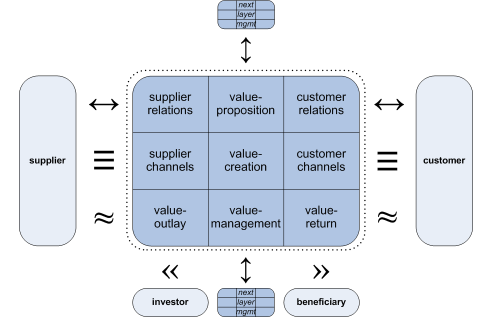
…or, much simplified, but the same overall idea, the kind of diagram we would scribble on the back of a napkin:
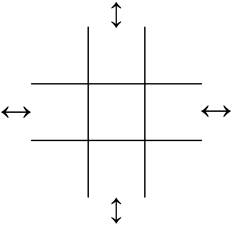
In the last article we started to explore the idea of layering, as seen, for example, in the hierarchical trees of management reporting-relationships that so evidently link to the Value-management cell of each service. The problem there is that this isn’t consistent: every organisation – and often every part of an organisation – will structure its management reporting-hierarchies differently from everyone else. And those management-structures keep changing almost on a day-to-day basis: we’ll soon get ourselves into a right old tangle if we try to use them as a basis for an architecture of the whole enterprise.
So what else could we use? Well, there’s the ‘BDAT’ layering – Business, Data, Applications, Technology – that’s used in TOGAF and so many other ‘enterprise’-architecture models:
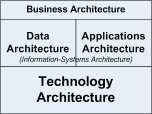
Common though this layering may be, it’s extremely misleading. In reality, it’s only one tiny subset of what we need: it’s a sort-of map of the enterprise in which the ‘layers’ are actually ‘distance from self’, where ‘self’ in this case is detail-level IT. This becomes clear when we look at the dependencies:
- our nominal task is to specify the architecture for the IT-infrastructure
- to identify the IT-infrastructure that we’ll need in the organisation, we first need to know the software-applications that will run on that infrastructure
- to identify the right applications, we need to understand the data that those applications will manage
- to identify the right data, we need to understand the business information that that data will underpin
- to identify the right information, we need to know the business meaning of that information
- to identify the business meaning, we need to know the strategic drivers of the business
- to identify the appropriate business-drivers, we need to know the nature of the enterprise – its vision and values
What happens in practice is that everything ‘not-IT’ gets bundled into a random, jumbled-up grab-bag labelled “business-architecture, which doesn’t matter because it’s not IT”. Which, to say the least, is not helpful… because, as a few EA frameworks such as FEAF do sort-of acknowledge, what we actually have in the enterprise is something much more like this:
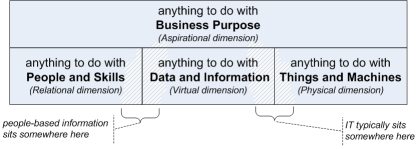
Every business-process exists for a purpose, and may consist of and/or be implemented by any combination of people, information/IT, things and machines. People-based ‘manual’ processes may be needed at any time to substitute for or take over from IT-based automation or machines: and to make that happen, they cannot be in different ‘layers’, but they are at the exact same level.
Once we understand that point, it becomes immediately clear that the standard BDAT stack is actually useless – or worse than useless – for anything than detail-level IT. And since IT is only a very small part of the overall enterprise, even in technology-intensive organisations – typically some 3-5% of costs and/or FTE – it’s clear that we’ll need something else with which to describe the required layering.
One IT-oriented ‘enterprise’-architecture framework that does get this part right is Zachman: what we need for this purpose are layers of abstraction, moving from abstract architecture to real-world implementation. Zachman describes the overall organisation in terms of five distinct layers: scope, business-model, system-model, technology-model, and detailed-implementation. For our purposes, though, we need one more layer at either end of the scale, to place the organisation in context of the broader enterprise, and to distinguish what was supposed to happen (‘detailed implementation’) from what actually happened in real-world practice. These layers are distinct from each other because they add something more at each transition ‘downward’ in the stack. For compatibility with Zachman, it’s best to start the layer-numbering at 0 (zero) rather than 1.
Row-0: Enterprise. This topmost level consists of just one item – the enterprise as a whole, defined by its vision and values. In the ISO-9000 model for quality-systems, this likewise described as the vision, the root-anchor for the quality-system:

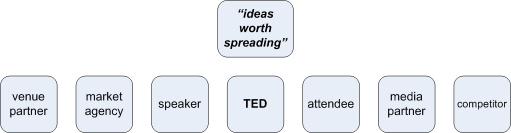
Row-1: Scope. At this level every entity is just a member of a list, without relationships or attributes as such. Given that the ‘parent’ is the enterprise, this would be a list of relevant players (roles) in the enterprise, with the organisation typically placed in the centre, and with all the other roles – customer, supplier, partner, competitor, regulator and so on – as other arbitrarily-labelled entities in the model:
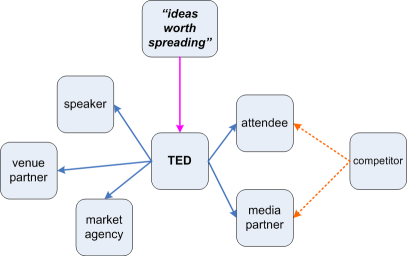
Row-2: Business model. At this layer we add relationships between the roles – in other words, we start to add the horizontal ‘supply-chain’ dimension to the vertical dimension of shared-value. (In the ISO-9000 model, this is the policy layer.) Each of these relationships is determined by the respective value-proposition we can offer to and/or be offered by each of these other players:
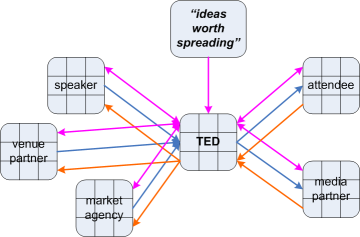
Row-3: System model (also known as Logical model). In this layer we start to include more details of attributes alongside the relationships, describing the internals of each high-level service and the flows between them. These are always abstract and generic: they define one or classes of possible implementations, but do not specify any particular technology or method. Most of what we would think of as ‘enterprise architecture’ or ‘business architecture’ will work at this level. (The Business Model Canvas sits part-way between row-2 and row-3: it summarises the relationships and value-propositions, but will rarely go into full formal detail of attributes and flows. In the ISO-9000 quality-system model, this is the procedure layer.) This is this first layer in which we begin to see the internal structure of each service, as described by the Enterprise Canvas:
Row-4: Design model (Zachman ‘Technology-model’, also known as Physical model). In this layer we provide detailed specifications for technologies, processes, interfaces, flows, protocols, skillsets and the like, translating the abstract system-models into requirements and project-plans for detailed implementation. (In the ISO-9000 quality-system model, this is the generic component of the work-instruction layer: specifications for every instance of a particular implementation, rather than for one specific implementation.) On the surface, the model looks much the same as for the row-3 System-model: the difference is that it describes an actual intended solution rather than a whole class of possible implementations.
Row-5: Operations model (Zachman ‘Detailed implementation’, also known as Action plan). This layer specifies the exact details of the full configuration of the service, as scheduled to be used and/or enacted on a specific day at a specific location for a specific purpose with specific staff, and so on. Again, we could describe it with the Enterprise Canvas in the same way as for row-3 and row-4, but there would be a lot more detail embedded in the model. For example, this is the CMDB (Configuration Management Database), the staff-rosters, the production-schedule and such-like; where the row-4 design-model might specify a database-server, for example, here we need to know the exact identifiers, types, configurations, physical locations and virtual addresses of the production-servers, fallback-servers, development-servers, test-servers, and all related support-equipment and switchgear. (In ISO-9000 terms, this is the specific rather than generic version of the work-instruction.) For architecture, the main use of this level of detail is to provide an understanding of qualitative concerns such as availability, adaptability, variance in loads, and so on.
Row-6: Action record. Unlike all the others, this layer is not a model of an intended future, but a record of the past. It carries the same level of detail as the row-5 action-plan, and in principle it should be exactly the same as row-5. In practice, though, it’s rare that it is the same: rostered staff are absent for any number of reasons, a server breaks down, people get switched around onto different machines, half our customers are at home watching the football match, a traffic-hold-up forces a change of the delivery-schedule – all manner of deviations from the expectations set down in the plan. Although there’s no chance of changing anything – for the simple reason that it’s all in the past – these records, and comparisons to the row-5 plans, are very important to process-designers, to organisational-learning specialists and many others who do extensive system-design (row-3 and row-4) in order to enhance operational effectiveness at the planning level (row-5). Enterprise architects can learn a great deal about real-world ebbs and flows here, about agility, resilience and emergent properties; and a solid understanding of the ‘bottom-up’ constraints evident here is an essential prerequisite for tackling the subtle yet serious pain-points and wicked-problems that are likely to be embedded deep within the structures of the organisation.
So that’s the key layering to use with the Enterprise Canvas: a structured sequence of transitions from most-abstract to most-concrete, with clear distinctions between each of these layers.
In the next article we’ll explore another type of layering provided by a link to Stafford Beer’s Viable System Model, which also acts as a precursor to the all-important topic of recursion. More later, anyway.
This is very valid way of viewing BMG and layering by abstraction. I would put BOS (Blue Ocean Strategy) between layers 1 and 2 (if not just 1). I need to think about this more.
Pat – I would agree that a fair part of BOS sits between layers 1 and 2 (assuming that you’ve remembered that layer-numbers here start at row-0, which is occupied only by the enterprise-vision and its associated values). But layer-1 is really just a list of players in the enterprise, and layer-2 is a summary of their relationships (in essence, their roles relative to each other and to this specific organisation), so layer-3 is the place where we start to work out the meat of the strategy. These moves between layers can be disorienting at first, but once you get the hang of what each layer actually does, it’ll make a lot more sense – and a lot easier to use BOS and the like.
Thanks again for the feedback, anyway. 🙂